[Pytorch] MNIST 문자 인식 모델
개발 환경 : google colab
모델 학습 하드웨어 : Intel(R) Core(TM) i5-1035G7 CPU @ 1.20GHz
MNIST(Modified National Institute of Standard an Technology) 데이터셋:

숫자 분류 구현 및 최적화하는 대표적인 예제이다.
1. Pytorch를 사용하기 위한 라이브러리 불러오기
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transfroms
- torch: PyTorch 라이브러리. 텐서 연산 및 신경망 구성에 사용
- torch.nn: 신경망 레이어를 정의할 때 사용
- torch.optim: 학습 과정에서 사용될 최적화 알고리즘을 위한 모듈
- torchvision: 이미지 관련 데이터셋과 전처리를 위한 모듈
- transforms: 데이터 전처리를 위한 모듈
Setting
1. GPU(CUDA)가 가능하면 GPU를 사용하고, 아니면 CPU를 사용하도록 설정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
print(device + " is available")
2. 학습 하이퍼파라미터 설정
learning_rate = 0.001
batch_size = 64
num_classes = 10
epochs = 10- learning_rate: 학습률 설정 (경사하강법에서 얼마나 빠르게 가중치를 업데이트할지를 결정).
- batch_size: 한 번에 학습에 사용할 데이터 샘플의 수.
- num_classes: MNIST 데이터셋의 클래스 개수는 10
- epochs: 전체 데이터셋을 학습할 반복 횟수
2. 데이터셋 로드 및 전처리
- 데이터의 텐서화
image: (28,28) -> tensor: (1, 28, 28) (1: 채널 수(흑백))
# MNIST 데이터셋 로드
train_set = torchvision.datasets.MNIST(
root = './data/MNIST',
train = True,
download = True,
transform = transfroms.Compose([
transfroms.ToTensor() # 데이터의 텐서화
])
)
test_set = torchvision.datasets.MNIST(
root = './data/MNIST',
train = False,
download = True,
transform = transfroms.Compose([
transfroms.ToTensor() # 데이터의 텐서화
])
)
print(f'Train set size: {len(train_set)}')
print(f'Test set size: {len(test_set)}')
print(f'Image size: {image.size()}')
print(f'Label: {label}')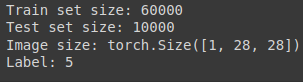
DataLoader: 데이터를 배치 단위로 로드하여 네트워크에 전달하는 역할이고, batch_size만큼 데이터를 나눠서 학습에 사용
- 4차원 텐서로 변환
(1,28,28) -> (batch_size,1,28,28)
from torch.utils.data import DataLoader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
images, labels = next(iter(train_loader))
print(f'Batch size: {images.size()}') # 배치의 크기 (64, 1, 28, 28)
print(f'Labels: {labels[:10]}') # 첫 10개의 라벨 확인
3. CNN model 정의
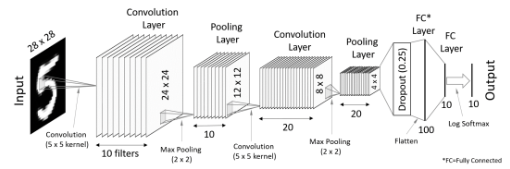
- 모델 시각화 도구
https://netron.app/
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # 1채널 입력, 10개의 필터, 5x5 커널
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) # 10채널 입력, 20개의 필터, 5x5 커널
self.drop2D = nn.Dropout2d(p=0.25) # 드롭아웃, 25% 확률로 무작위 뉴런 비활성화
self.mp = nn.MaxPool2d(2) # 2x2 크기의 Max Pooling
self.fc1 = nn.Linear(320, 100) # 완전 연결층: 320 -> 100
self.fc2 = nn.Linear(100, 10) # 완전 연결층: 100 -> 10 (클래스 수)
def forward(self, x):
x = F.relu(self.mp(self.conv1(x))) # Conv1 -> ReLU -> Max Pool
x = F.relu(self.mp(self.conv2(x))) # Conv2 -> ReLU -> Max Pool
x = self.drop2D(x) # 드롭아웃
x = x.view(x.size(0), -1) # 데이터를 평탄화 (Flatten)
x = self.fc1(x) # 완전 연결층 1
x = self.fc2(x) # 완전 연결층 2
return F.log_softmax(x, dim=1) # log Softmax로 확률 값 출력
ConvNet class 생성자 init 내용
(1) Convolution layer 1 - nn.Conv2d(1, 10, kernel_size=5 )
- (5,5) kernel을 적용시키면 (28,28) -> (24,24) 로 출력
- 입력 채널 1에서 10개의 출력 채널로 변환
=> (64, 1, 28, 28) -> (64, 10, 24, 24)
(2) Convolution layer 2 - nn.Conv2d(10, 20, kernel_size=5)
- (1)과 마찬가지로 layer 설계
(3) Dropout 2D layer - nn.Dropout2d(p=0.25)
- 채널 단위로 25% 확률로 드롭아웃 작용
- spatial dimension 변화 없이 정규화
=>(64,20,10,10) -> (64,20,10,10)
(4) MaxPool 2d layer - nn.MaxPool2d(2)
- 2*2 윈도우(window)로 spatial dimension을 절반으로 축소
=> (64,20,20,20) -> (64,20,10,10)
(5) Fully Conneted layer 1 - nn,LInear(320,100)
- 320개의 입력 뉴런에서 100개의 출력 뉴런으로 변환
=> (64,320) -> (64,100)
(6) Fully Conneted layer 2 - nn.LInear(100,10)
- 100개의 입력 뉴런에서 10개의 출력 뉴런으로 변환
=> (64,100) -> (64,10)
ConvNet class 멤버함수 forward 내용
(1) 첫 번째 레이어 : x = F.relu(self.mp(self.conv1(x)))
- self.conv1(x) : (64,1,28,28) -> (64,10,24,24)
- 연산: 5x5 커널로 합성곱 수행
- 작업: 특징 추출 시작, 10개의 서로 다른 특징 맵 생성
- self.mp() : (64,10,24,24) -> (64,10,12,12)
- 연산: 2x2 윈도우로 최대값 추출
- 작업: 공간적 크기 축소, 주요 특징 보존
- F.relu() : (64,10,12,12) -> (64,10,12,12)
- 연산: max(0, x) - 음수값을 0으로 변환
- 작업: 비선형성 추가, 그래디언트 소실 방지
(2) 두 번째 레이어: x = F.relu(self.mp(self.conv2(x)))
- self.conv2(x) : (64,10,12,12) -> (64,20,8,8)
- 연산: 5x5 커널로 합성곱 수행
- 작업: 특징을 더 쪼개기
- self.mp() : (64,20,8,8) -> (64,20,4,4)
- 연산: 2x2 윈도우로 최대값 추출
- 작업: 특징 맵 크기 추가 축소
- F.relu() : (64,20,4,4) -> (64,20,4,4)
- 연산: max(0, x)
- 작업: 두 번째 비선형성 추가
(3) 드롭아웃 : x = self.drop2D(x) : (64,20,4,4) -> (64,20,4,4)
- 연산: 25% 확률로 채널 전체를 0으로 설정
- 작업: 과적합 방지, 모델의 일반화 능력 향상
(4) 평탄화 : x = x.view(x.size(0), -1) : (64,20,4,4) -> (64, 320)
- 연산: 첫 번째 차원(배치 사이즈)을 제외한 모든 차원을 펼침
- 작업: 전결합층 입력을 위한 1차원 벡터 변환
(5) 첫 번째 완전연결층: x = self.fc1(x) : (64,320) -> (64, 100)
- 연산: 선형 변환 W₁x + b₁
- 작업: 특징 공간 차원 축소, 분류를 위한 특징 조합
(6) 두 번째 완전연결층: x = self.fc2(x) : (64,100) -> (64,10)
- 연산: 선형 변환 W₂x + b₂
- 작업: 최종 클래스 점수 계산
(7) Log softmax : return F.log_softmax(x, dim=1) : (64,10) -> (64,10)
- 연산: log(softmax(x)) = log(exp(xi) / Σexp(xj))
- 작업:
- 클래스별 확률의 로그값 계산
- 수치적 안정성 향상
- 크로스 엔트로피 손실 계산 용이
4. 학습 ( 공부 예정)
for epoch in range(epochs):
avg_cost = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 기울기 초기화
hypothesis = model(data) # 모델을 통해 예측
cost = criterion(hypothesis, target) # 손실 계산
cost.backward() # 역전파 계산
optimizer.step() # 파라미터 업데이트
avg_cost += cost / len(train_loader)
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
(1) epochs : 전체 데이터셋을 반복 학습하는 횟수
(2) 배치 데이터 로드 및 출력 결과 대입
- data : 입력 이미지 배치 (64,1,28,28)
- target : 정답 레이블 배치 (64,)
(3) 그래디언트 초기화 : optimer.zero_grad()
- 이전 배치에서 계산된 그래디언트 제거
- 그래디언트 누적 방지
(4) 순전파 : hypothesis = model(data)
- 위에서 만든 model에 입력 데이터 통과 시키기
(5) 손실 계산 : cost = criterion(hypothesis, target)
- 예측값과 실제값의 차이 계산
- CrossEntropyLoss 계산 과정
- 예측값의 Log Softmax 계산 (모델 설계에서 포함함)
- 정답 레이블에 해당하는 로그 확률 선택
- 음의 로그 우도 계산
(6) 역전파 : cost.backward()
- 손실에 대한 각 파라미터의 그래디언트 계산
- 연쇄 법칙(Chain Rule) 사용
- 과정
- 출력층부터 시작
- 각 층(layer)을 거슬러 올라가며 그래디언트(gradient 계산
- requires_grad=True인 모든 텐서에 대해 .grad 속성 업데이트
(7) 파라미터 업데이트
- 계산된 그래디언트를 사용하여 모델 파라미터 업데이트
- 학습률(learning rate)에 따라 업데이트 크기 조절
Adam optimizer의 경우:
- 1차 모멘텀(momentum) 계산
- 2차 모멘텀(velocity) 계산
- 편향 보정
- 파라미터 업데이트
(8) 평균 손실 계산 : avg_cost += cost / len(train_loader)
- 현재 epoch의 평균 손실 누적
- len(train_loader): 총 배치 수
- 전체 데이터셋에 대한 평균 성능 측정
(9) 학습 진행 상황 출력

5. 평가
model.eval() # 모델을 평가 모드로 전환 (dropout, batch_norm 해제)
with torch.no_grad(): # 기울기 계산 비활성화
correct = 0
total = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
out = model(data)
preds = torch.max(out.data, 1)[1] # 예측된 클래스 값
total += len(target)
correct += (preds == target).sum().item() # 정확도 계산
print('Test Accuracy: ', 100.*correct/total, '%')
(1) 모델 평가 모드 설정 - model.eval()
- 학습 시 사용된 확률적 요소들 비활성화
- 일관된 추론 결과 보장, 전체 네트워크 활성화 유지
(2) 그래디언트 계산 비활성화 - with torch.no_grad();
- 추론 시 역전파가 필요없으므로 모든 연산에서 그래디언트 추적 비활성화
(3) 테스트 데이터 처리
(4) 모델 추론 - out = model(data)
(5) 예측 클래스 계산 - preds = torch.max(out.data, 1)[1]
- out.data: 출력 텐서의 값만 선택
- torch.max(tensor, dim=1):
- dim=1 (클래스 차원)을 따라 최대값 검색
- 반환값: (최대값, 최대값의 인덱스)
- [1]: 인덱스 값만 선택 (예측 클래스)
(6) 정확도 계산
- 예측값과 실제값을 비교하여 맞은 개수에 전체 시도 개수를 나눔
6. Real test
import matplotlib.pyplot as plt
import numpy as np
num_images = 10
model.eval()
# 예측할 데이터와 실제 레이블을 가져오기
data_iter = iter(test_loader)
images, labels = next(data_iter)
images, labels = images.to(device), labels.to(device)
# 모델 예측
with torch.no_grad():
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
fig = plt.figure(figsize=(12, 6))
for idx in range(num_images):
ax = fig.add_subplot(2, 5, idx + 1)
ax.imshow(images[idx].cpu().squeeze(), cmap='gray') # 이미지를 시각화 (채널을 제거)
ax.set_title(f'True: {labels[idx].item()}, Pred: {predicted[idx].item()}') # 실제 레이블과 예측값 표시
ax.axis('off') # 축 제거
plt.tight_layout()
plt.show()
(1) 예측 - _, predicted = torch.max(outputs.data, 1)
- torch.max로 예측 클래스 추출
- outputs: (batch_size, 10) 형태의 로그 확률
- predicted: (batch_size,) 형태의 예측 클래스
(2) 이미지 표시- ax.imshow(images[idx].cpu().squeeze(), cmap='gray')
- images[idx]: 단일 이미지 선택
- .cpu(): GPU 텐서를 CPU로 이동 (Matplotlib는 CPU 텐서만 처리 가능)
- .squeeze(): 차원 축소 (1, 28, 28) → (28, 28)
- cmap='gray': 흑백 이미지로 표시
