[PaperReview] Mean teachers are better role models: Weight-averaged consistency
[https://arxiv.org/abs/1703.01780]
요약
이 논문은 반지도 학습(semi-supervised learning)에서 성능을 향상시키기 위한 Mean Teacher 방법을 제안합니다. 기존의 Temporal Ensembling 기법은 훈련 데이터의 예측값을 지수 이동 평균(EMA, Exponential Moving Average)으로 유지하고, 이에 부합하지 않는 예측을 패널티화하여 일관성을 높이는 방식입니다. 그러나 이 방법은 한 에포크(epoch)마다 목표 값(targets)을 업데이트하기 때문에, 대규모 데이터셋을 학습하는 데 비효율적이라는 단점이 있습니다.
주요 기여
Mean Teacher 기법 제안:
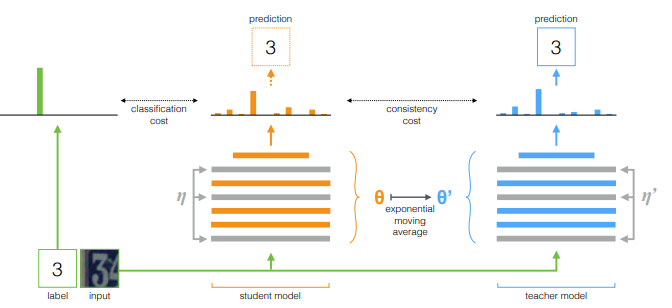
- Temporal Ensembling 대신, 모델의 가중치를 EMA를 이용해 평균을 내는 방식을 사용하여 일관성 목표를 설정함.
- **"스튜던트 네트워크(student network)"**와 **"티처 네트워크(teacher network)"**를 사용하며, 티처 네트워크는 스튜던트 네트워크의 과거 가중치들의 평균값을 유지하는 방식.
Mean Teacher의 장점:
- 효율적인 반지도 학습: Temporal Ensembling보다 빠른 일관성 있는 학습
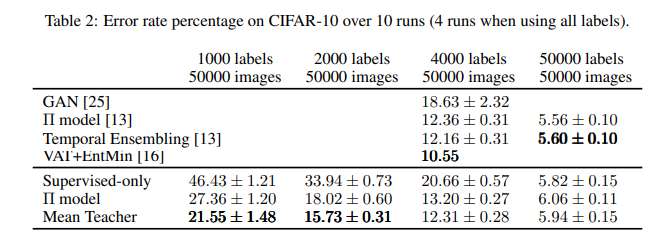
- 더 높은 테스트 정확도: table1, table 2의 결과처럼 적은 수의 레이블(label)만으로도 높은 성능
실험 결과:
- SVHN 데이터셋에서 250개의 적은 레이블만 사용하여 4.35%의 오류율을 달성 (Temporal Ensembling은 1000개 레이블 필요)
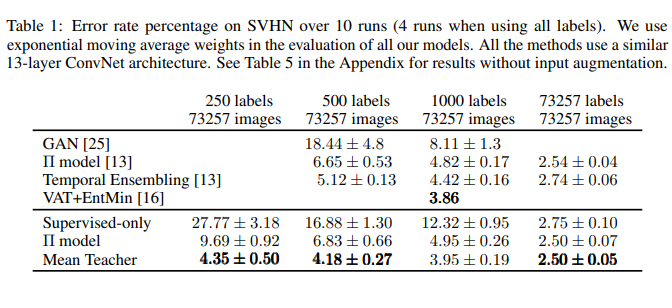
- CIFAR-10 데이터셋**에서 4000개의 레이블이 넘어가면 Temporal Ensembling과 별 차이는 없지만,
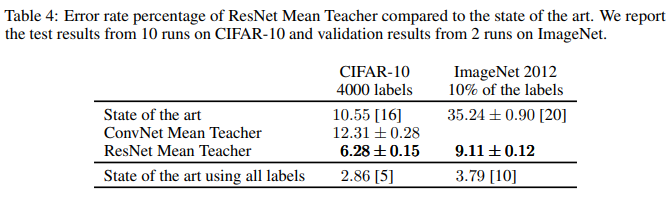
- ImageNet 2012 데이터셋에서 10%의 레이블만 사용해 오류율을 35.24% → 9.11%\*\*로 크게 줄임
결론
Mean Teacher 방법은 기존의 Temporal Ensembling보다 더 적은 라벨 데이터로도 더 높은 정확도를 보장하며, 대규모 데이터셋에도 효율적으로 적용될 수 있습니다. 특히, 신경망 아키텍처를 잘 설계하면 성능이 더욱 향상될 수 있음을 실험적으로 입증함
주요 개념
Π Model :
Temporal Ensembling : 단일 모델을 활용하여 각 epoch의 moving average 결과 값과 현재 예측값의 차이를 줄이는 방식
EMA : 최근값에 더 높은 가중치를 두는 시계열 데이터를 전처리할 때 사용(사용: pandas.DataFrame.ewm + mean)