std::deque
덱(deque)는 배열과 리스트 기반 컨테이너의 장점이 섞여 있는 형태이다.
- push_front(), pop_front(), push_back(), pop_back() 동작이 O(1) 시간 복잡도로 동작
- 모든 원소에 대해 임의 접근 동작이 O(1) 시간 복잡도로 동작
- 덱 중간에서 원소 삽입 또는 삭제는 O(n) 시간 복잡도로 동일, 최대 n/2 단계 (n은 deque의 크기)

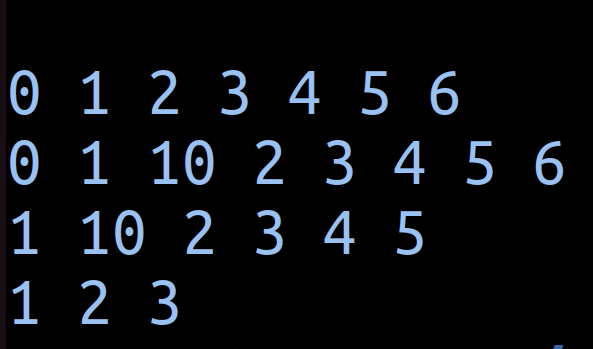
Deque의 사용 사례
- 양방향 탐색이 필요한 경우: 덱을 활용한 너비 우선 탐색(BFS) 또는 양방향 BFS에서는 탐색의 방향을 유연하게 조절해야 할 때 덱을 활용하여 구현할 수 있습니다.
- 슬라이딩 윈도우 문제: 주어진 배열에서 고정된 크기의 윈도우를 이동시키며 최댓값이나 최솟값을 찾는 문제에서 덱을 사용하면 각 윈도우에서 효율적으로 최대/최솟값을 찾을 수 있습니다.
- 캐시 구현 (LRU 캐시): 최근에 사용한 데이터는 덱의 한쪽에 추가하고, 오래된 데이터는 반대쪽에서 제거하는 방식으로 최소 최근 사용(Least Recently Used, LRU) 알고리즘을 구현할 수 있습니다.
- 문자열 및 수식의 회문 검사: 문자열이 회문인지 검사할 때 덱에 문자를 하나씩 삽입하고 양쪽 끝에서 문자를 비교하면서 검사를 진행할 수 있습니다.
컨테이너 어댑터
- 이미 존재하는 컨테이너로 만들어진 컨테이너
- 코드에 더 의미를 부여하고 싶거나, 의도하지 않는 함수를 사용하지 못하도록 제한하고 싶거나, 특별한 인터페이스 제공
std:stack
- 양방향 탐색이 필요한 경우:deque에서 필요한 인터페이스만 제공함(덱의 축소판)
- 후입선출(LIFO): 마지막에 넣은 요소를 가장 먼저 제거합니다.
- 입력과 출력이 한쪽 끝에서만 발생: 요소 추가와 제거 모두 스택의 "top" 위치에서만 이루어집니다.
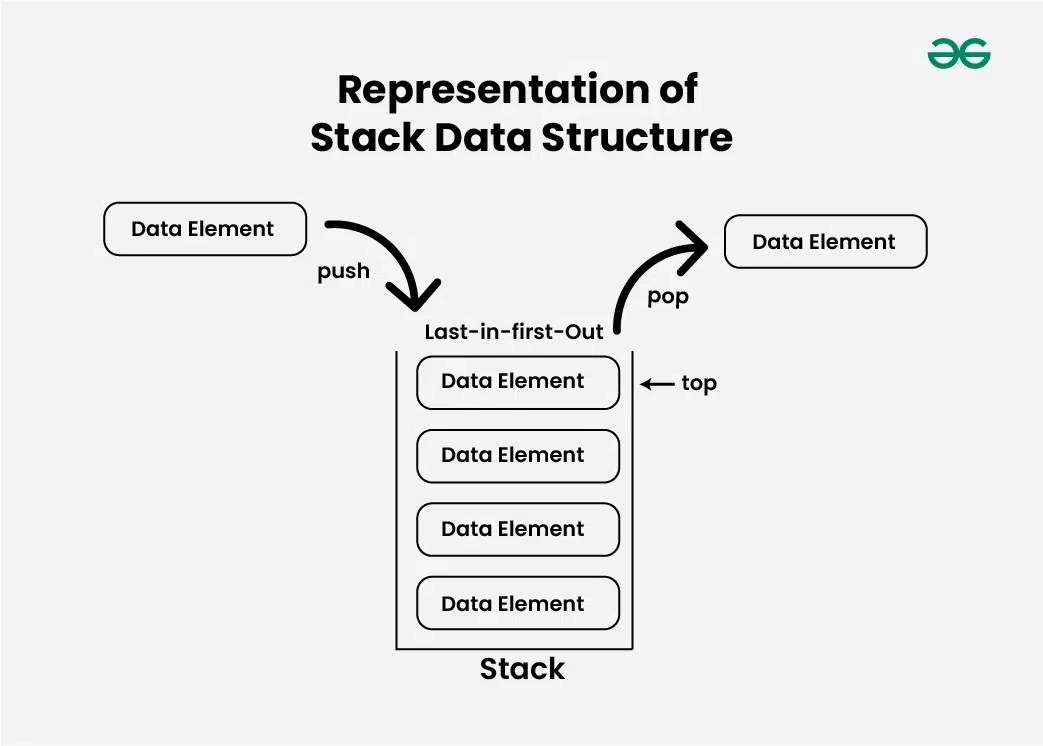
stack를 사용해야 할 때
- 함수 호출 스택: 프로그램의 함수 호출이 중첩될 때 호출 순서대로 반환하기 위해 사용합니다.
- 재귀 알고리즘: 재귀 함수 호출 시, 각 함수의 상태를 스택에 저장해두고, 최상위 함수부터 반환하면서 결과를 얻습니다.
- Undo 기능: 워드 프로세서나 그래픽 편집 프로그램에서 이전 상태로 돌아가는 기능을 구현할 때, 마지막 작업부터 역순으로 되돌리기 위해 사용합니다.
- 수식 계산: 후위 표기식 계산기 등에서 연산을 중첩하여 처리해야 할 때 사용됩니다.
- 스택의 구현은 덱을 기본 컨테이너로 활용한다.
- 몇몇 경우는 객체 생성 시 템플릿 매개 변수로 사용할 컨테이너 지정
#include <iostream>
#include <vector>
#include <list>
#include <stack>
#include "func.hpp"
int main(){
std::stack<int, std::vector<int>> stk;
std::stack<int, std::list<int>> stk2;
}std::queue
- 선입선출(FIFO): 먼저 들어온 요소가 먼저 나갑니다.
- 입력은 뒤에서, 출력은 앞에서 발생: 요소는 "뒤"에 추가되고 "앞"에서 제거됩니다.
- 데이터의 이동이 많아 연결리스트 형태가 유리하다.

queue를 사용해야 할 때
- 대기열 관리: 프로세스 스케줄링, 네트워크 요청 처리 등에서 데이터가 순차적으로 처리되어야 할 때 사용됩니다.
- 이벤트 처리 시스템: 게임이나 GUI 프로그램에서 사용자 입력이나 이벤트를 처리할 때, 입력된 순서대로 반응하기 위해 사용합니다.
- BFS 알고리즘: 그래프 탐색 알고리즘인 너비 우선 탐색(BFS)에서, 탐색해야 할 노드를 순서대로 저장하고 꺼내기 위해 사용합니다.
- 메시지 큐: 시스템에서 데이터를 순서대로 전달해야 할 때 큐로 관리합니다.
std:: priority_queue
- 자동 정렬: 요소를 삽입하면 자동으로 정렬되며, 가장 높은 우선순위를 가진 요소가 맨 위에 위치합니다.(기본적으로 내림차순)
- 힙(Heap) 구조: priority_queue는 내부적으로 힙(Heap)을 사용해 효율적으로 요소를 관리합니다.

사용자 정의 우선순위
사용자 정의 타입의 우선순위 큐를 만들기 위해 비교 연산자를 정의
#include <iostream>
#include <queue>
#include <string>
struct Person {
std::string name;
int age;
// 비교 연산자 오버로드 (age 기준으로 정렬)
bool operator<(const Person& other) const {
return age < other.age; // 나이 내림차순 정렬
}
};
int main() {
std::priority_queue<Person> pq;
pq.push({"Alice", 30});
pq.push({"Bob", 25});
pq.push({"Charlie", 35});
while (!pq.empty()) {
Person p = pq.top();
std::cout << p.name << " (" << p.age << ")" << std::endl;
pq.pop();
}
return 0;
}priority_queue를 사용해야 할 때
- 데이터가 우선순위가 있을 때 (가장 중요한 요소부터 처리해야 할 때).
- 항상 가장 큰(혹은 작은) 값을 빠르게 접근해야 할 때.
- 예: 작업 스케줄링, 이벤트 관리, 최단 경로 알고리즘 (다익스트라) 등.
'Computer Science > Data Structure&Algorithm' 카테고리의 다른 글
| std:forward_list, std:list (0) | 2024.10.26 |
|---|---|
| std::array, std::vector (1) | 2024.10.26 |

